CSAPP malloclab
首先先跑一遍课本上的代码,内存利用率和吞吐量都不是很好。尤其是吞吐量,非常糟糕。
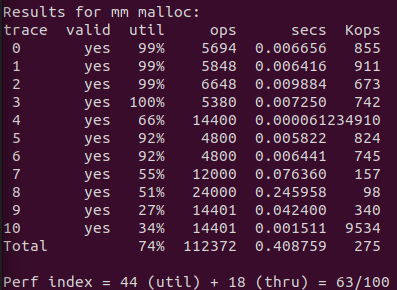
e9.17
将首次适配搜索改为下一次适配搜索。
为此,定义 rover 指向上一次分配的块。在 mm_init 中,rover 初始化为 heap_listp。编写 next_fit 用于实现下一次适配搜索算法:从 rover 开始,一直找到结尾块。再从 heap_list 开始,一直找到 rover。
一个易错点是,我们还需要修改 coalesce。因为在执行合并时,有可能 rover 正指向当前块,但当前块被释放后与前一个块进行了合并。此时,需要让 rover 指向前一个块。
可以看出吞吐量有了显著提升,并且内存利用率也没有下降(貌似与课本描述有些出入)。
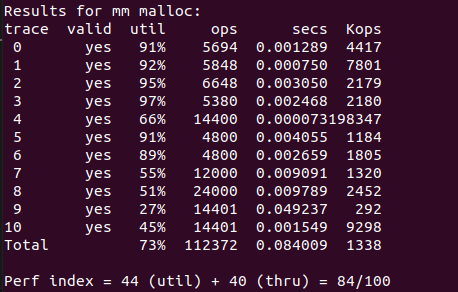
e9.18
只在空闲块同时维护头部和脚部,分配块只维护头部。
具体地,使用次低位来标记前一个块是否被分配。
首先,mm_malloc 需要进行修改,因为分配块只需要头部,所以在计算 asize 时只用加上单字而非双字。相应地,place 函数在剩余空间大于 DSIZE 时就可以进行分割,而非 2*DSIZE。
mm_free 中,释放时只需要将头部的最低位置零,同时添加上脚部。并且对后面的块的头部的次低位置零,若该块未被分配,则脚部也置零。
coalesce 中,case 2 需要将头部和脚部都置为 2,case 3和case 4将头部和脚部的低三位设置为前一个块的低三位。
extend_heap 中,新分配的块的倒数第二位需要继承结尾块的倒数第二位,在初始化时,结尾块低三位需要置为 3。
改起来比较费力,调试了很久,出了很多错误。更加糟糕的是,结果比起原来还低了一分。猜测是优化掉结尾块并没有显著提高内存利用率,但是 place 中分割条件的更改可能不太适合 trace10 的模式。
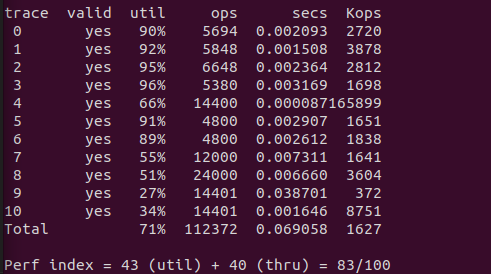
(试图把分割条件改回原来的 2*DSIZE,但是出现了 mm_realloc did not preserve the data from old block 的错误,没想明白是为什么)
Implicit free lists
基于上面的讨论,采用 next_fit,对分配块同样维护尾部(e9.18 的优化既难写,而且没什么效果)。
修改 realloc
对 realloc 进行一点小修改:如果 size 未超过 oldsize,那么直接更改块的大小。更进一步的,如果后一个块为空闲块,判断条件变为 size 不超过 oldsize 加上空闲块的大小。
可以看出 trace10 有了一点小改进,但是效果不是很明显。
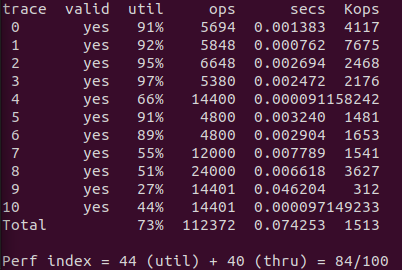
修改 find_fit
因为当前内存利用率是限制得分的瓶颈,所以考虑多找几个空闲块,选择最优的那一个。但是经过测试,不仅内存利用率提升有限,而且吞吐量下降严重。
小结
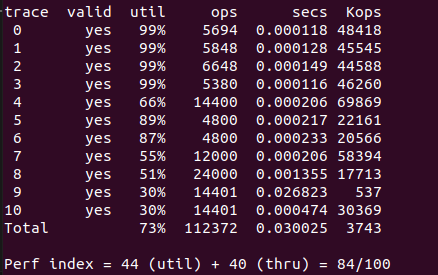
最终使用隐式空闲链表获得了 84 分。采用了 next_fit 分配方式,每个块均有头部和脚部,并且对 realloc 进行了一点优化。
事实上首先首次适配 + realloc 的修改可以在 trace9 和 trace10 中取得较高的内存利用率,但是吞吐量降低,最终的得分也没有超过 84 分。
Segregated Free Lists
在头部添加 14 个头结点,分别作为大小在 内块的头结点。
对于每个空闲块,需要在头部再添加指向下一个块和上一块的指针,简记为后指针和前指针,各 32 位。
为了方便,再定义一些宏:
1 | |
分别是取得一个块的前后指针以及取得一个块在链表中的前后块。
定义 select_class 函数,用于根据 size 选择对应的头结点。
同时,定义 add_block 和 del_block,用于在链表中添加和删除空闲块。添加块时,将该块插入链表的第一个,需要将前一个块的后指针,后一个块的前指针和该块的前后指针进行修改。删除块时,需要将前一个块的后指针和后一个块的前指针进行修改。注意该块没有后一个块的情况。
考虑何时调用 add 和 del:由于每次添加空闲块都需要调用 coalesce 函数,所以将 add_block 放在里面非常合适。当一个块被分配或和前后的块合并时,需要调用 del_block。
find_fit 比较容易实现。先找到对应的头结点,开始执行首次适配。如果没有,就移动到下一个头结点。
可以说是比较难实现,大概花了两天的时间,还完全推倒重构了一次,不过好在是独立实现了出来。但遗憾的是,它在性能上也没有什么提升(之前因为没有对改变大小的块重新插入链表导致得分反而下降,还玉玉了一阵子)。
一些改进
- segregated free lists 按照地址从小到大进行组织。
- CHUNKSIZE 调整为 。 (有种调整超参数的玄学感)
- todo:
- realloc 进行优化,网上有一个 97 分的写法,但是没太看明白优化的逻辑在哪里。
- 使用平衡树维护空闲块(感觉不一定会有很好的效果)。
最终分数
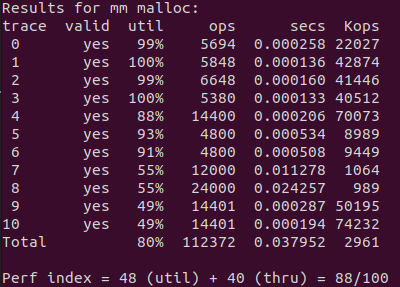
最终获得了 88 分,最后几个 trace 表现得不是很好。
这个实验做起来可以说是相当痛苦,不过还是独立完成了,取得了一个不错的结果。
撒花!